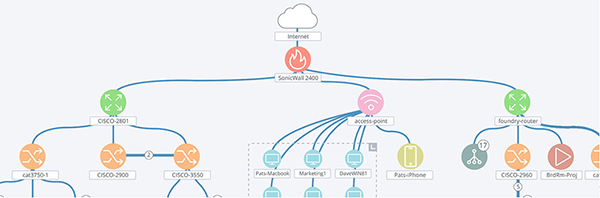
The first line of defense in a network is the access control list (ACL) on the edge firewall. Some vendors call these firewall rules or rule sets or something similar. To keep the discussion focussed, this post will look only at the Cisco ASA, but many of the ideas are applicable to just about every device on the market.
Cisco uses ACLs for many other purposes besides controlling access. ACLs can define which routes will be distributed over a routing protocol. They can control quality of service (QoS) rules and other policies as well. But for this article I just want to talk about the ACLs that filter traffic flowing into, through, and out of the firewall. Just about every firewall implementation will need this kind of ACL.
The challenge is that while these ACLs can be fairly simple in concept, they quickly become large and unwieldy if they aren’t carefully organized and managed.
5 general rules for building ACLs
I use several general rules when building and applying ACLs to interfaces on an ASA firewall. Note that this is simply how I do it. They aren’t hard rules, but they are based on many years of experience and a lot of mistakes and places where I painted myself into a difficult corner.
My goal is always to make the intent of the configuration as clear as possible, and to make it easy to maintain and update the firewall over time.
I always construct my rules using the command-line interface (CLI). I don’t like using the Cisco ASDM web interface to configure ASA firewalls because I don’t find it makes anything easier to understand or faster to deploy.
When I first started using ASA firewalls, I did use ASDM. But most of us who work with these systems regularly find the CLI easier in the long run.
One of the biggest differences is that the ASDM interface automatically creates a lot of object groups that wind up having arbitrary and meaningless names. This alone I consider to be so unhelpful that I always encourage administrators to build their ACLs from the CLI.
The first rule is to always apply ACLs inbound on all interfaces. Every interface should have an ACL, even if it’s a trivial single line.
I don’t like to apply ACLs outbound on the interfaces because I want to use the firewall’s internal compute and memory resources as efficiently as possible. I don’t want to receive a packet, perform address translation and application inspection, scan it against IDS rules, and then put it in the outbound buffer, only to drop it. That’s rather inefficient. Since firewalls are often performance bottlenecks in networks, I would prefer to apply those resources more carefully.
This is true for the modern Cisco ASA 5500x devices that have the internal SourceFire IDS/IPS devices, which are the focus of this particular article, but also true for essentially every next-generation firewall on the market. If we know we’ll never accept a packet from North Korea, let’s just drop it and not bother to inspect it any further.
There are exceptions, of course. Cisco wouldn’t have included the ability to apply outbound ACLs if they weren’t needed. But I would consider instances where outbound rules are needed as corner cases that can often be avoided if you design your rule sets more carefully.
The second rule is to name the ACL after the interface on which the rule will be applied. I like to name my main interfaces inside and outside. If there additional interfaces such as DMZs, I try to give them clear and simple names as well, like dmz.
The ACL applied to the inbound path on my inside interface will be inside_in. The one on the outside interface will be outside_in. If I had an outbound ACL, it might be called outside_out.
Normally I modify these ACLs incrementally, simply adding or deleting individual lines one at a time. However, if I need to do a wholesale change, I generally keep the old ACL and create a new one, but add a simple revision number to the name, such as inside_in_2. This way, it’s very easy to roll back the change to the old version if there’s a problem.
The third rule is to use remarks in your ACLs to internally document your intentions. The more you can make the configuration of your firewall self-documenting, the easier it will be to manage it going forward. (I’ll show some specific examples of remark lines a little later).
The fourth rule is to use object-groups. An object-group is a convenient way of organizing things like IP addresses or protocols. Using object-groups allows you to create an access rule for one group of hosts to access another group of hosts over a common set of protocols with a single command, as long as you’ve already defined those groupings. The other big advantage of object-groups is that you can re-use them.
For example, I might want to block a particular set of malicious IP addresses from ever accessing my network from the outside. If I use the same object-group on the inside interface, I can also prevent anybody inside my network from ever accessing these same malicious external hosts. And if I add a new host to that object-group, I automatically update both those inbound and outbound rules.
The other important thing to mention about object-groups is that they should have meaningful names. If you have an object-group for standard web protocols like HTTP and HTTPS, give it a name like WebProtocols, making it obvious what it is and how you plan to use it.
And finally, the fifth rule is that it’s really important to make your ACL as specific as possible. Don’t permit “any” hosts if you can narrow it down. Make those “permit” rules as specific as possible. The same goes for protocols. Don’t permit all IP protocols if you really mean a particular protocol. Firewalls are security devices, so don’t undermine your security.
Overall ACL structure
ACLs are executed sequentially for each new session. If there’s a match, either permitting or denying the packet, the firewall stops checking. So order matters. I’ve seen many cases where certain lines in an ACL never have an effect because an earlier rule overrides them.
I like to build my ACLs in a structured way. First, I include a relatively small and very specific whitelist. It includes things that I know are always allowed, and overrides any blacklist rules that might come later.
For example, I might want to always permit a VPN tunnel from the static IP address of a remote office. At one client site, I created a rule that would be updated regularly that included the IP address of the hotel where a senior executive was staying that week. I removed it when they returned to the office.
Most of the time, I also include a general blacklist, then all of the specific rules.
Start each section with a remark explaining what it is. Each individual rule should also have a separate remark. If the client has a good change control system, I like to also include the ticket number and initials of the engineer making the change in each of the individual rule remark lines.
The following configuration fragment shows a very simple example, with only a single rule in each section.
!
access-list outside_in remark Section 1 - Specific whitelist
access-list outside_in remark Temporary exception - #50662 - 2016-10-20 - KD
access-list outside_in extended permit tcp object-group SPECIAL_DEVICES any eq http
access-list outside_in remark Section 2 - General blacklist
access-list outside_in remark Suspicious Ranges - #11246 - 2015-11-05 - KD
access-list outside_in extended deny ip object-group SuspiciousRanges any
access-list outside_in remark Section 3 - General whitelist
access-list outside_in remark web servers - #24548 - 2016-08-19 - KD
access-list outside_in extended permit tcp object-group any WebServers object-group WebProtocols
access-list outside_in remark Section 4 - Specific rules
access-list outside_in remark mail relay - #10456 - 2015-07-29 - KD
access-list outside_in extended permit tcp object-group MailRelay object-group MailServer object-group MailProtocols
!
access-group outside_in in interface outside
That last “access-group” command is what we use to apply this particular ACL to the interface. In this case, it’s applied inbound to the interface named outside.
The blacklist
Now let’s look at the sections in more detail. The general blacklist is usually a list of sites or IP address ranges representing geographic regions that I will never accept anything from. For example, if the organization never expects legitimate traffic from a residential broadband ISP in suburban Moscow or sub-Saharan Africa, block it. And if you’re being attacked from a web hosting service in Romania, block it. I often do this all in a single object-group that I call SuspiciousRanges.
Note that this is also why I put my specific whitelist and temporary exceptions above the general blacklist. If there’s a legitimate customer in Lagos, Nigeria, or an executive who likes to holiday in Moscow, I can put these specific addresses into my whitelist without weakening my blacklist.
Then one of my daily activities is to monitor the firewall logs for people attacking my network, and to add their IPs to this object group. I always look up the IPs against DNS and see what they are. If the source is an ISP in a country where I never expect to see legitimate traffic, then I might block the whole allocated range for that ISP. Otherwise, I might just block the single host that’s attacking me.
!
object-group network SuspiciousRanges
description Hosts and networks to be blocked
network-object 175.45.176.0 255.255.252.0
network-object host 192.168.254.254
The above example object-group has only two useful lines. This particular object-group will generally grow over time to be extremely large.
I like to keep a spreadsheet just for this rule, explaining why I’ve included each line. If it was an attack, then I include the date of the attack and the specific IP addresses that originated the attack. This way, if there’s ever a complaint from a user saying that a legitimate host has been blocked, I can look back and see whether that particular host is collateral from an overly general rule. This can happen in particular with large web hosting services, where IP addresses might be re-used, or where there are many customers and only some of them are malicious.
Counters and statistics
One of the most useful but neglected features of Cisco ASA ACLs is the statistical data provided by the “show access-list” command. This command conveniently provides a counter of the number of times each rule was matched.
And, in the case of object-group lines, which could include hundreds or thousands of individual entries, it breaks out the hit counts for each individual entry. These counts give you an instant way of telling whether a particular rule is being used.
Such information can be helpful when trying to troubleshoot why a particular traffic pattern is either passing or being blocked incorrectly. Suppose, for example, that you’re trying to allow a particular external network to access some sensitive DMZ server, but it isn’t working. To accommodate the access, you probably added a narrowly defined “permit” command to your outside_in ACL. Use the “show access-list outside_in” command and find the line you created for this purpose. If it has a hit count of zero, then you know some other command higher up in the ACL is blocking your special access.
The other thing I often use the counters in the “show access-list” output for is to see whether specific lines are being used at all. If they’re never used, they might be unnecessary, making them candidates for removal next time I’m cleaning up my firewall configuration.
It’s also useful to remember that every ACL ends with an implicit “deny all” rule. This means that anything not explicitly allowed will be rejected. However, it’s often convenient to make this explicit and end the ACL with a “deny ip any any” rule.
The advantage to doing so is that the “show access-list” command will give you statistics on how often packets are being rejected by falling off the end of the ACL. If I’m doing formal statistical analysis, then I can add up all of the individual counters and get reliable percentages of how many packets are being rejected or accepted by each individual command.
A few additional thoughts
One of the more interesting features of these ACLs is the ability to use Fully Qualified Domain Names (FQDN). It’s a relatively new feature, which I presume Cisco added because every other firewall vendor had such a feature. However, I have to say I don’t really like to use DNS-based rules in my firewall ACLs.
Here’s my worry. Suppose somebody knew that I trusted, say, www.auvik.com by name in my firewall. They could launch an attack in which they hit my firewall with bogus DNS packets and trick it into accepting packets from some other network.
There’s a workaround to this problem, though. If you use FQDN-based ACL entries, you can (and should) enable the “dns-guard” feature on your firewall. It’s an inspection rule that validates DNS responses.
Another thing to consider when building ACLs is that they’re static and based purely on Layer 3 and 4 features like IP addresses and port numbers. This doesn’t really help you if you’re concerned about more sophisticated attacks.
For example, if I use an ACL to allow HTTP access to my web server from the Internet, the firewall passes all of those HTTP packets. In fact, it will pass anything that has the right TCP port information, regardless of whether it’s actually HTTP. And it will completely miss more sophisticated attacks like SQL injections, cross-site scripting, and so forth. So I like to think of my firewall ACL as simply a first order traffic filter to give the intrusion detection/prevention system (IDS/IPS) a slightly easier job.
Cisco’s current generation of ASA 5500x firewalls include the option of running SourceFire IDS/IPS software on a virtual machine inside the firewall. Or you could use some other vendor’s IDS/IPS. The important thing is to remember that you aren’t secure just because you’ve built a rock solid ACL.
The post Implementing ACLs on Cisco ASA Firewalls appeared first on Auvik Networks.